최근 몇 년 동안 대규모 텍스트 말뭉치(Text Corpora)에 대해 사전 학습된 대규모 언어 모델(LLM)이 출시되면서 자연어 처리 시스템 구축을 위한 새로운 패러다임이 등장했다.
수십 년 동안 사용되어 왔으며 신중하게 선별되고 레이블이 지정된 훈련 세트에 의존하는 기존의 텍스트 애플리케이션 구축 방법론 대신, LLM은 프롬프팅(Prompting)이라는 새로운 기법을 탄생시켰다.
프롬프트 패러다임에서는 사전 학습된 LLM에 텍스트 스니펫(snippet)이 입력으로 제공되며, 이 입력에 대한 적절한 완성을 제공할 것으로 기대된다. 이러한 입력은 다음과 같이 모델에 요청되는 작업을 설명할 수 있다:
Translate the following sentence from English to Spanish. The cat jumped over the moon.
다음의 결과를 볼 수 있다.
El gato saltó por encima de la luna.
프롬프트의 놀라운 점은 이러한 입력값을 적절하게 설계할 수 있다면 단일 LLM을 몇 개(또는 0개)의 학습 샘플만으로 요약, 질문 답변, SQL 생성, 번역 등 다양한 작업에 적용할 수 있다는 점이다.
이러한 LLM의 성능은 입력에 따라 크게 달라지기 때문에 연구자와 업계 실무자들은 이러한 머신 러닝의 성능을 최대한 끌어내기 위해 프롬프트를 설계하는 일련의 원칙과 기술을 제공하기 위한 프롬프트 엔지니어링 분야를 개발했다.
이러한 이유로 프롬프트 엔지니어링은 프롬프트 프로그래밍 또는 자연어 프로그래밍이라고도 불린다.
이 글에서는 대규모 언어 모델에 적용된 프롬프트 엔지니어링에서 가장 흥미로운 연구, 기술 및 사용 사례에 대해 포괄적으로 검토해 보겠다. 또한 보다 효과적인 프롬프트 엔지니어가 되기 위한 일련의 실행 가능한 단계를 제공하는 것이 저의 목표이다.
TL;DR :

프롬프트 엔지니어링을 위한 원칙
대규모 언어 모델에 대한 프롬프트는 일반적으로 소수 샷 및 제로 샷의 두 가지 형식 중 하나를 사용한다. 소수 샷 설정에서는 번역 프롬프트에 다음과 같은 문구가 표시될 수 있다:
Translate from English to Spanish.
English: I like cats.
Spanish: Me gustan los gatos.
English: I went on a trip to the bahamas.
Spanish: Fui de viaje a las bahamas.
English: Tell me your biggest fear.
Spanish:여기서 주목해야 할 점은 프롬프트에 관심 있는 작업을 올바르게 수행하는 방법을 보여주는 몇 가지 예제가 포함되어 있다는 것이다.
다양한 연구에 따르면 이러한 데모를 제공함으로써 LLM이 작업을 수행하는 방법을 즉석에서 학습한다.
제로 샷 설정에서는 프롬프트에 예제가 제공되지 않으므로 번역 작업은 다음과 같이 공식화 할 수 있다:
Translate the following sentence from English to Spanish.
The cat jumped over the moon.최근 연구에 따르면 LLM에서 흥미로운 프롬프트 현상이 나타났다.
예를 들어, Lu 등은 몇 번의 샷으로 구성된 환경에서 프롬프트에 예제가 제공되는 순서에 따라 거의 완벽한 추측과 무작위 추측의 성능이 달라질 수 있음을 관찰했다.
이 관찰은 LLM 크기(즉, 큰 모델도 작은 모델과 동일한 문제를 겪음)와 데모에 사용된 예제의 하위 집합(즉, 프롬프트에 예제가 많다고 해서 분산이 줄어들지 않음)과는 무관하다. 또한 주어진 예제 순서의 성능은 모델 유형에 따라 달라지지 않는다.
그런 다음 개발 데이터 세트 없이 최적의 프롬프트 순서를 생성하기 위해 엔트로피 기반 프로빙 기법을 제안한다. 이 접근 방식은 다양한 프롬프트 템플릿에서도 모델의 편차를 강력하게 줄이는 것으로 나타났다.
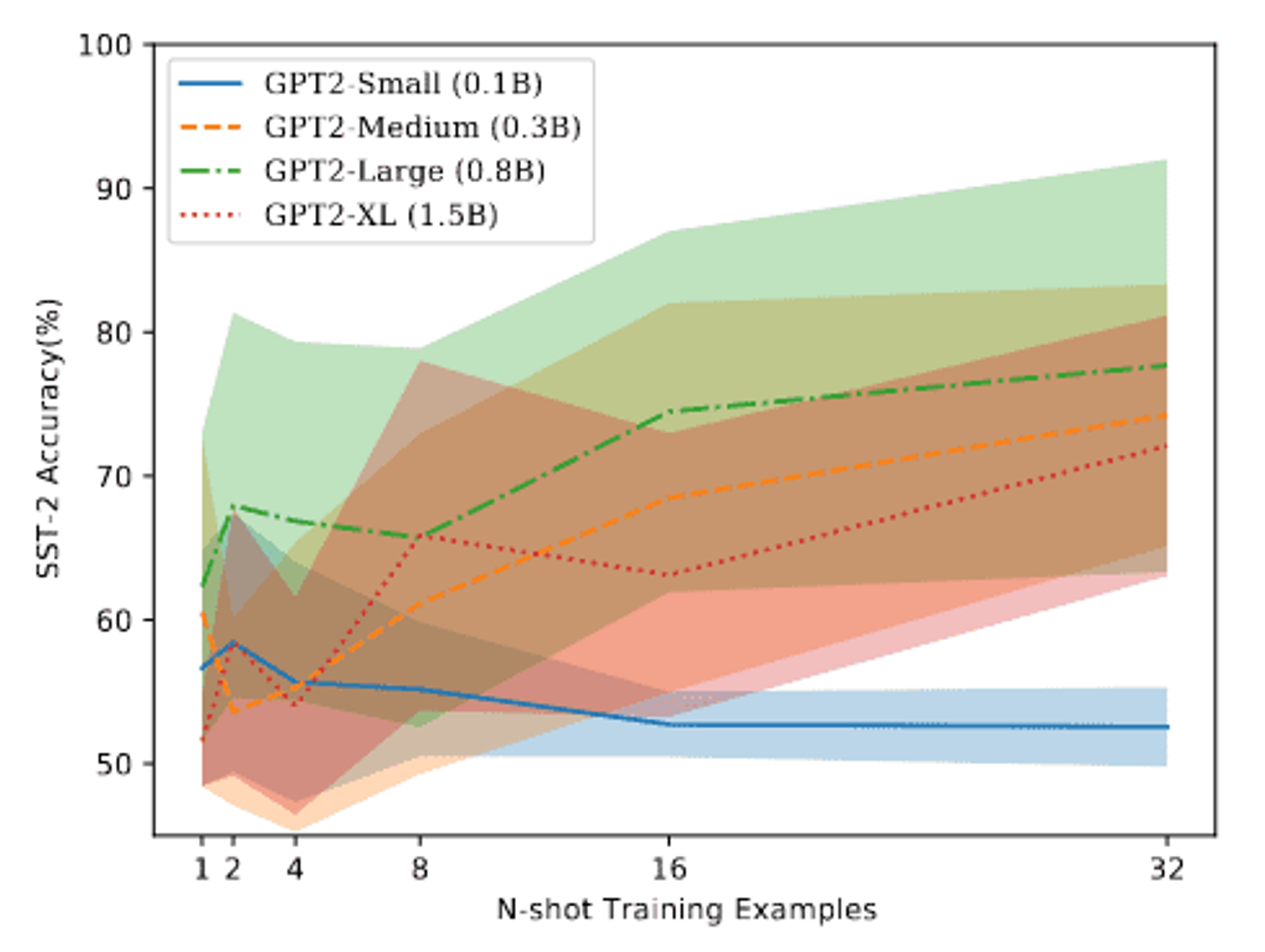
Zhao와 Wallace 등은 소수 샷 프롬프트의 불안정성에 대한 심층 연구도 수행했다. 이 연구에 따르면 소수의 샷 프롬프트에서 LLM은 세 가지 유형의 편향을 겪는다:
- 다수 라벨 편향. 자주 나타나는 훈련 샘플 레이블을 예측하는 경향이 있다.
- 최근 편향. 프롬프트가 끝날 무렵에 답을 예측하는 경향이 있다.
- 공통 토큰 편향. 사전 학습 데이터에 자주 나타나는 답을 예측하는 경향이 있다.
그런 다음 이러한 편향 중 일부를 완화하기 위해 고안된 보정 기법을 설명하여 분산 감소와 30%의 절대 정확도 향상을 보여준다.
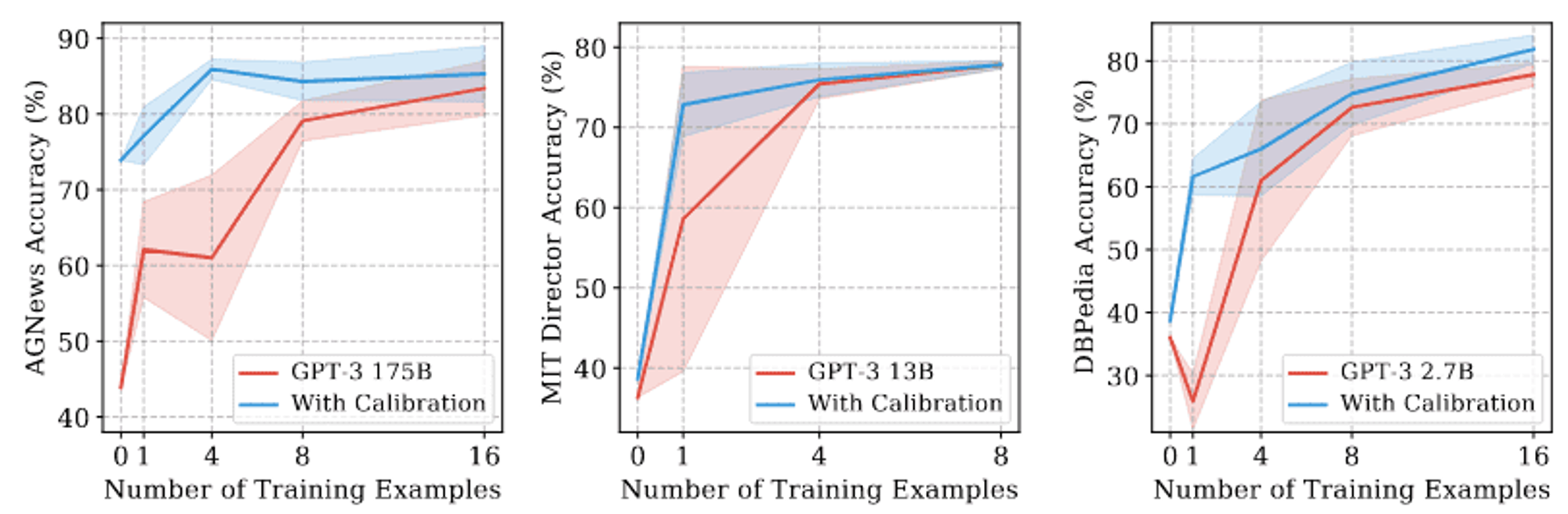
레이놀즈와 맥도넬의 다른 연구에 따르면, few-shot learning 은 사실 잘못된 명칭이며, 실제로 LLM은 사전 학습 데이터에서 학습한 기존 작업 공간에서 적절한 작업을 찾기 위해 few-shot 예제를 사용한다.
이는 매우 신중하게 설계된 프롬프트 엔지니어링의 필요성을 더욱 정당화합니다. 따라서 프롬프트를 설계할 때 적용해야 할 몇 가지 원칙을 제안한다:
- 초등학교 2학년도 이해할 수 있도록 이 단락을 번역하거나 바꾸기 등의 작업에는 선언적이고 직접적인 기표어를 사용한다.
- 과제에 맞춤형 형식이 필요한 경우, 몇 장면의 예시가 독립적인 샘플이 아니라 모델에 의해 전체적으로 해석될 수 있음을 인식하고 몇 장면의 데모를 사용한다.
- 간디나 니체에게 과제 해결을 요청하는 것과 같이 인물이나 특징적인 상황을 의도의 대리로 사용하여 과제를 지정한다. 여기서 LLM의 유추에 대한 정교한 이해를 활용할 수 있다.
- "이 프랑스어 문장을 영어로 번역해줘"라고 말하거나 프랑스어 문장 주위에 따옴표를 추가하는 등 신중한 구문 및 어휘 프롬프트 공식을 사용하여 가능한 완성 출력을 제한한다.
- 단계별 추론을 통해 모델이 문제를 하위 문제로 세분화하도록 유도하라.
앤드류 칸티노는 프롬프트 엔지니어링을 위한 몇 가지 실용적인 팁과 요령도 제공했다.
- LLM은 완성된 결과물에 문체의 일관성을 유지하는 경향이 있으므로 입력 내용이 문법적으로 정확하고 작문 품질이 좋은지 확인한다.
- N개의 항목 목록을 생성하는 대신 하나의 항목을 N번 생성해라. 이렇게 하면 언어 모델이 반복적인 루프에 갇히는 것을 방지할 수 있다.
- 출력 품질을 향상시키려면 많은 완성을 생성한 다음 휴리스틱 방식으로 순위를 매긴다.
미슈라(Mishra) 등은 GPT3에 효과적인 프롬프트를 구성하는 방법에 대한 광범위한 분석을 수행했다. 이들은 임의의 프롬프트가 성공적인 완료를 생성할 가능성을 높이기 위한 일련의 reframing밍 기법을 제안한다.
- 다른 예제의 low-level 패턴을 사용하여 주어진 프롬프트를 LLM이 더 쉽게 이해할 수 있도록 한다.
- 지침을 글머리 기호 목록으로 명확하게 항목화한다. 예를들어 '다음에 해당하지 않는 것을 질문으로 만들지 마세요'와 같은 부정적인 문장을 '다음에 해당하는 질문을 만드세요'로 바꾸어라.
- 가능하면 top-level 작업을 병렬 또는 순차적으로 실행할 수 있는 여러 하위 작업으로 세분화다.
- 매우 구체적인 과제를 풀려고 할 때는 반복적이고 일반적인 문장을 피해라. 예를 들어 수학 문제에 대해 '다음 질문에 답하세요'라고 말하는 대신 '다음 질문에 대한 답을 계산하세요'라고 말한다. 숫자를 더하거나 빼야 합니다... 를 추가한다.
연구진은 리프레이밍된 프롬프트가 few-shot이나 zero-shot 설정에서 성능을 크게 향상시키고, 모델 유형 전반에 걸쳐 성능을 일반화하며, 심지어 (더 작은) 기존 감독 모델을 능가할 수 있음을 입증했다.
자동화된 프롬프트 생성
수동 프롬프트 엔지니어링의 까다로운 특성을 고려할 때, 자동화된 프롬프트 기술을 개발하기 위한 많은 유망한 연구 노력이 있었다.
Shin, Razeghi, and Logan et al 등은 일련의 트리거 토큰을 통해 자동으로 프롬프트를 생성하는 그라데이션 가이드 검색 기법을 개발했다. 이 기법을 마스크 언어 모델(MLM)에 적용했을 때 감정 분석, 자연어 추론, 사실 검색과 같은 작업에서 인상적인 성능을 보여줬으며, 심지어 데이터가 적은 환경에서도 미세 조정된 모델을 능가하는 성능을 보였다.
Jiang과 Xu 등은 마이닝 및 의역 방법을 사용하여 MLM 시스템을 위한 최적의 프롬프트를 생성하는 방법을 제안하여 관계형 지식 추출의 정확도를 거의 10% 향상시켰다.
Li 등은 학습된 연속 벡터(접두사라고 함)를 사용하여 다른 매개변수가 고정된 생성 모델의 입력에 추가하는 대체 기법을 개발했다. 연구진은 GPT2 및 BART 생성에 접두사 튜닝을 사용했으며, 전체 데이터 및 적은 데이터 설정에서 1000배의 파라미터로 미세 튜닝된 모델을 능가하는 성과를 거둘 수 있었다.
프롬프트 사용 사례 설문 조사
LLM의 마법 중 하나는 단 몇 가지의 프롬프트 기술만으로 수많은 작업을 합리적으로 잘 수행할 수 있다는 점이다.
일부 연구에서는 이러한 새로운 능력이 매개변수 크기 측면에서 특정 규모의 대규모 언어 모델에서만 나타난다고 주장하기도 한다.
LLM은 등장 이후 지식 탐색, 정보 추출, 질문 답변, 텍스트 분류, 자연어 추론, 데이터 세트 생성 등 다양한 분야에서 보다 공식적인 학문적 맥락에서 적용되어 왔다.
LLM을 사용하여 구축된 다양한 애플리케이션을 살펴보고 싶으시다면 이 링크를 참조하세요.
또한 입사 지원서부터 아빠의 농담까지 모든 것을 프롬프트 기반으로 생성하는 깔끔한 데모 모음을 보려면 Gwern의 글을 확인하세요. 이러한 몇 가지 사례를 보면서 크리에이티브 작업의 패러다임에 큰 변화가 다가오고 있다는 확신이 들었다.
신속한 엔지니어링 팁과 요령에 대한 최신 정보를 얻고 싶으시다면 Riley Goodside의 피드를 확인해라.
프롬프트 엔지니어링을 위한 인프라
프롬프트 엔지니어링은 아직 초기 단계의 개념이지만 애플리케이션 개발을 위한 새로운 인터페이스가 필요한 것은 분명하다. 보다 쉬운 프롬프트 설계를 위한 인프라를 제공하는 여러 프로젝트가 출시되었다.
Bach와 Sanh 등은 프롬프트 엔지니어링을 위한 모범 사례를 체계화하고 크라우드소싱하기 위해 통합 개발 환경인 PromptSource를 구축했다. 여기에는 데이터 연결 프롬프트를 정의하기 위한 템플릿 언어와 프롬프트 관리를 위한 일반 도구가 포함된다.
이와 관련된 작업으로 Strobelt는 프롬프트 변형을 실험하고, 프롬프트 성능을 추적하고, 프롬프트를 반복적으로 최적화할 수 있는 편리한 시각적 플랫폼인 PromptIDE를 개발했다.
최적의 프롬프트에 대한 검색 프로세스를 체계화하면 프롬프트 엔지니어링을 위한 AutoML 스타일의 프레임워크가 하나의 결과물이 될 수 있다는 점에서 이러한 작업의 일반적인 방향이 마음에 든다.
지금까지 프롬프트에 대한 많은 연구가 단일 단계 프롬프트 실행에 중점을 두었지만, 보다 정교한 애플리케이션을 구현하려면 여러 프롬프트 시퀀스를 함께 엮어야 한다. Wu 등은 이를 LLM 체인이라는 개념으로 공식화하여 이러한 다단계 LLM 애플리케이션을 설계하는 도구로 PromptChainer를 제안합니다.
이 플랫폼의 강력한 장점은 프롬프트 단계뿐만 아니라 외부 API 호출 및 사용자 입력을 함께 연결하여 프롬프트 엔지니어링을 위한 거의 웹플로우 인터페이스를 형성한다는 것입니다.
프롬프트 엔지니어링 보안
LLM 애플리케이션을 구축할 때 관찰되는 한 가지 흥미롭고 우려스러운 현상은 프롬프트 기반 보안 익스플로잇의 출현이다.
보다 구체적으로, 여러 사람들이 신중하게 만들어진 입력을 활용하여 LLM이 백엔드에서 사용하는 '비밀' 프롬프트를 뱉어낼 수 있을 뿐만 아니라 자격 증명이나 기타 개인 정보를 유출할 수 있다고 지적했다. 이 때문에 자연스럽게 구식 SQL 인젝션 공격과 비교되고 있다.
현재로서는 이 문제를 해결할 수 있는 강력한 메커니즘이 없다.
대신 사람들은 입력 형식의 형식을 달리하여 해결 방법을 제안했지만, 향후 사용 사례에서 LLM이 점점 더 많은 기능을 제공하게 될 경우 이러한 취약점을 방지하기 위해 더 많은 작업이 필요한 것은 분명하다.
최종 생각
프롬프트 엔지니어링은 언어 기반 애플리케이션 개발 방식을 근본적으로 바꿀 수 있다.
이 분야에서 흥미로운 연구가 진행되고 있지만, 프롬프트가 과연 예술인지 과학인지에 대한 철학적 질문이 남아있다.
현 시점에서 단언하기는 어렵지만, 연구자와 실무자들은 이러한 LLM의 역학 관계와 이들이 수행할 수 있는 작업을 이해하기 위해 상당한 에너지를 쏟고 있다.
저는 개인적으로 프롬프트를 효과적인 Google 검색을 설계하는 것에 비유하는 것을 좋아한다.
Google 검색 엔진에 대해 작업을 해결하는 쿼리를 작성하는 데는 분명히 더 좋은 방법과 나쁜 방법이 있다. 이러한 차이는 Google이 내부에서 수행하는 작업의 불투명성 때문에 존재한다.
Google 검색어를 작성하는 것은 모호한 활동처럼 보일 수 있지만, 사람들이 마법의 Google 알고리즘을 최대한 활용할 수 있도록 돕기 위해 SEO라는 전체 분야가 등장했다.
마찬가지로, 프롬프트는 LLM을 길들이고 매개변수에서 포착된 힘에서 가치를 추출하기 위한 노력임이 분명합니다. 오늘날에는 사이비 과학처럼 보일 수 있지만, 이를 체계화하려는 노력이 있고 이러한 시도를 완전히 무시하고 작업하기에는 이러한 LLM에서 포착할 수 있는 가치가 너무 많다.
프롬프트 엔지니어가 미래에는 실제 직책이 될까요, 아니면 현재와 같은 열등한 모델이 반복되는 과정에서 생겨난 유물에 불과한 것일까요, 아니면 GPT-100이 쓸모없게 만들까?
다시 말하지만 미래를 예측하기는 어렵지만 저는 자동 프롬프트 기술에 대해 매우 낙관적이다.
최적의 학습률을 찾기 위해 약간의 마법이 필요한 하이퍼파라미터 튜닝과 같은 방식으로 프롬프트 엔지니어링이 발전할 수도 있지만, 여전히 올바른 파라미터를 더 쉽게 찾을 수 있는 알고리즘(그리드 검색, 랜덤 검색, 어닐링 등)을 개발해 왔다.
어쨌든 대규모 언어 모델에 대한 프롬프트에서 흥미로운 일들이 일어나고 있다. 이 분야를 계속 지켜보자.
출처 : https://www.mihaileric.com/posts/a-complete-introduction-to-prompt-engineering
'Technology > AI' 카테고리의 다른 글
| EA 와 E/ACC의 네러티브 줄다리기 게임 (1) | 2023.11.29 |
|---|---|
| AI가 어떤 비즈니스도 힘을 실어줄 수 있다. - Andrew Ng (0) | 2023.08.08 |
| AI 혁명 - 초인공지능(ASI)로 가는길 (1) (0) | 2023.07.30 |
| Chat GPT를 활용한 프롬프트 엔지니어링의 3원칙 (1) | 2023.07.25 |
| 2023 AI 인덱스 보고서 - Stanford University (0) | 2023.07.24 |



